Cybersecurity
Overview
While many of us may have used Generative AI, few have experience securing Generative AI applications. This article provides an overview of Generative AI security, focusing on Large Language Models (LLMs). It is designed for cybersecurity professionals in the U.S. Government who may not have direct experience with AI, Generative AI, or LLMs. We will cover U.S. agencies setting AI policy, organizations providing AI security guidance, the NIST AI Security governance framework, the OWASP Top 10 Vulnerabilities for LLM applications, Generative AI Security solution categories, and more.
Key U.S. Government Agencies Setting AI Policy and Guidance
Many other U.S. Government agencies are involved in policy and guidance in more specialized spaces, for example homeland security, energy, international policy, defense or intelligence use cases.
Relevant Policies and Guide
Non-Governmemnt Organizations Provided AI Security Guidance and Resources
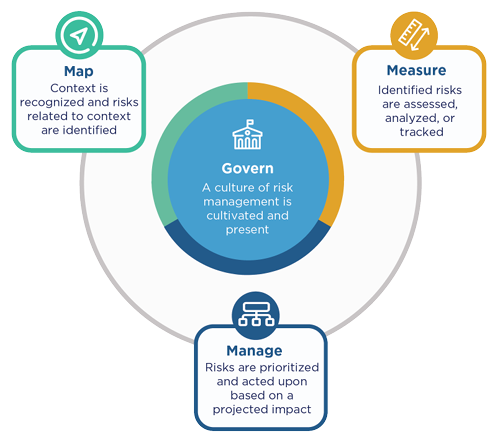
NIST AI Risk Management Framework
The AI RMF Core provides outcomes and actions that enable dialogue, understanding, and activities to manage AI risks and responsibly develop trustworthy AI systems. The Core is composed of four functions: GOVERN, MAP, MEASURE, and MANAGE. Each of these high-level functions is broken down into categories and subcategories. Categories and subcategories are subdivided into specific actions and outcomes.
The NIST AI RMF, and accompanying AI RMF Playbook, are great foundational AI security resources to build upon. However, more practical and specialized approaches are needed for Generative AI and LLM security to be effective. This is where the OWASP Top 10 for LLM Applications come into play.
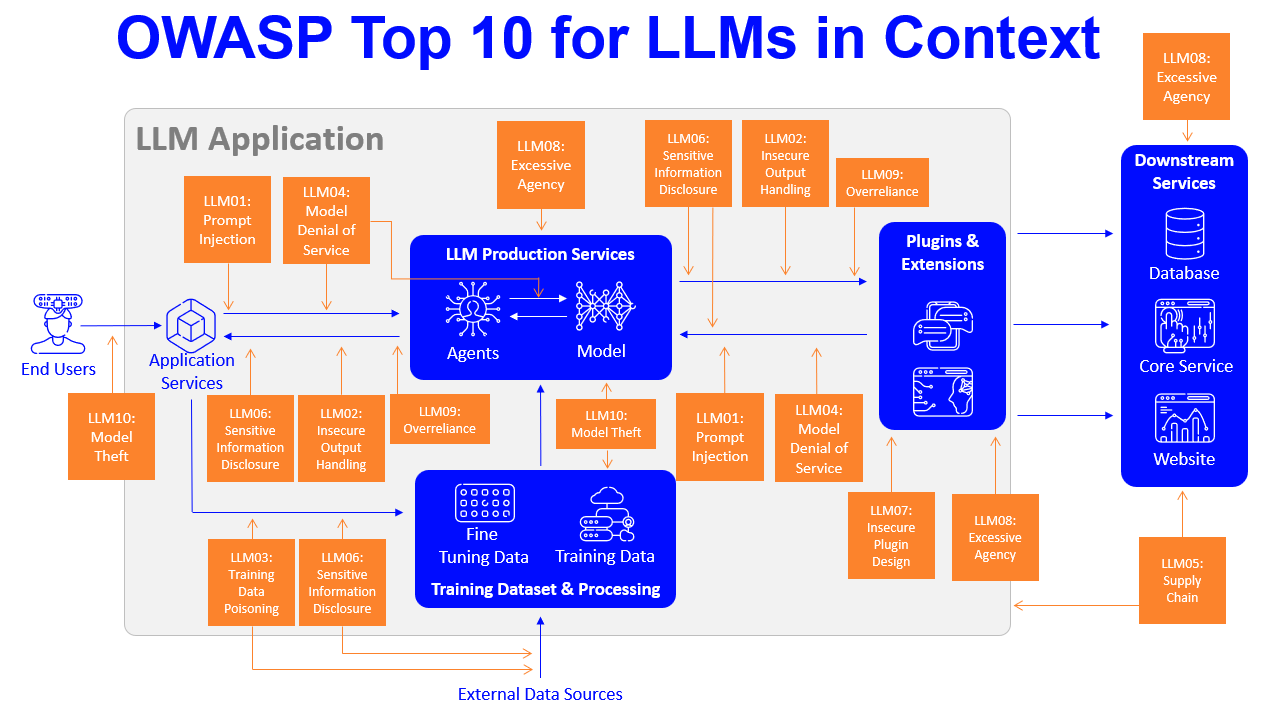
OWASP Top 10 Vulnerabilities for LLM Applications
Generative AI Security Solution Categories
Solution Categories from OWASP LLM and GenAI Security Solutions Landscape Guide help clients consider new emerging technology (I.E. product) capabilities to secure their GenAI environments from the very beginning of development to public consumption by millions of users.
Some of these new emerging security solution groups include:
| Security Solution | Description |
| LLM Firewall | An LLM firewall is a security layer specifically designed to protect large language models (LLMs) from unauthorized access malicious inputs, and potentially harmful outputs. This firewall monitors and filters interactions with the LLM blocking suspicious or adversarial inputs that could manipulate the model’s behavior. It also enforces predefined rules and policies, ensuring that the LLM only responds to legitimate requests within the defined ethical and functional boundaries. Additionally, the LLM firewall can prevent data exfiltration and safeguard sensitive information by controlling the flow of data in and out of the model. |
| LLM Automated Benchmarking | LLM-specific benchmarking tools are specialized tools designed to identify and assess security weaknesses unique to LLMs. These capabilities include detecting potential issues such as prompt injection attacks, data leakage, adversarial inputs, and model biases that malicious actors could exploit. The scanner evaluates the model’s responses and behaviors in various scenarios, flagging vulnerabilities that traditional security tools might overlook. |
| LLM Guardrails | LLM guardrails are protective mechanisms designed to ensure that LLMs operate within defined ethical, legal, and functional boundaries. These guardrails help prevent the model from generating harmful, biased, or inappropriate content by enforcing rules, constraints, and contextual guidelines during interaction. LLM guardrails can include content filtering, ethical guidelines, adversarial input detection, and user intent validation, ensuring that the LLM outputs align with the intended use case and organizational policies |
| AI Security Posture Management | AI-SPM has emerged as a new industry term promoted by vendors and analysts to capture the concept of a platform approach to security posture management for AIƬ including LLM and GenAI systems. AI-SPM focuses on the specific security needs of these advanced AI systems. Focused on the models themselves traditionally. The stated goal of this category is to cover the entire AI lifecycle – from training to deployment – helping to ensure models are resilient, trustworthy, and compliant with industry standards. AI-SPM typically provides monitoring and address vulnerabilities like data poisoning, model drift, adversarial attacks, and sensitive data leakage. |
Conclusion
By understanding the key policies, frameworks, and best practices outlined in this article, security professionals can begin building a deeper understanding and formulate plans to secure Generative AI and LLM applications. Implementing these measures will help mitigate risks and ensure the safe and ethical use of AI technologies. Swish has experience developing Generative AI solutions as well as securing them. If you’d like to collaborate on project please request a discussion here.