
Blog
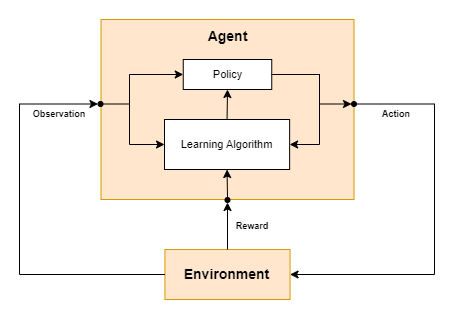
Reinforcement Learning (RL) is a type of Machine Learning (ML) that finds optimal solutions to sequential decision problems through trial-and-error. This involves monitoring interactions between an agent and an uncertain environment. The agent makes decisions and performs actions. The environment provides feedback and facilitates state changes often in an unrestrained domain.
A policy is maintained by the agent in policy-based RL. The policy governs the best action to take given the current state of the agent’s environment. The policy is updated and optimized based on incremental rewards for behaviors and decisions that ultimately lead to efficiently achieving a long-term objective.
The reward is a measure of the quality of a sequence of actions that led the agent to the current state. There are scalar feedback signals that indicate how well the agent is doing and these help the agent learn to make better decisions over time. Feedback is not completely instantaneous so the learning algorithms are able to find instances where it may be better to sacrifice immediate reward to gain longer-term, cumulative rewards.
Unlike Supervised and Unsupervised Learning, the key concept in RL is that there are no existing target variables or inherent groupings; only the reward signal. Also, while conventional ML algorithms specialize in specific subtasks, RL algorithms are often flexible and adaptable enough to determine context and resolve ambiguities and therefore are often better suited to help solve problems in real-world situations. RL is typically more computationally expensive than other ML algorithms but like other ML algorithms, they can sometimes become unstable depending on the number of system parameters.
Advances in ML have created new opportunities for progress in critical areas such as health, education, energy, and the environment. Representatives from numerous Federal agencies constitute the National Science and Technology Council’s Subcommittee on Machine Learning and Artificial Intelligence which monitors the state-of-the-art in ML and AI and fosters “sharing of knowledge and best practices about ML and AI by the Federal Government.”
It is relatively well-known that ML-driven projects and automation can improve customer experience and reduce costs of existing services in the federal government. RL is becoming an increasingly important tool for federal professionals because of its ability to solve complex and dynamic problems, some of which are subtasks in the following areas.
Although ML can perform a myriad of functions, it is not always easy to integrate these technologies into government operations and missions. One of the leaders in the implementation of RL (and ML in general) is H2O.ai. They have a great wiki site that details many aspects of ML, including RL.

Their primary objective as a company is to democratize AI. In lieu of hiring a large team of programmers, data scientists, and data engineers, the H2O.ai platform automates and standardizes many of the routine operations involved in setting up ML pipelines and accommodating the data lifecycle. This comes in handy when having to deal with government security requirements and other bureaucratic hurdles.
In the AWS DeepRacer context, the agent is the vehicle. The environment can either be the virtual race track supported by Amazon SageMaker and AWS RoboMaker, or a specially-built real-world track. The DeepRacer RL algorithms rely on optimal policies to explore and exploit the environment.
The action space used by DeepRacer can either be discrete or continuous. Swish is currently experimenting with discrete action spaces. This means that the parameters of the vehicle (agent), such as steering angle or speed, are defined by a finite number of distinct values. Theoretically, a discrete action space will converge faster than a continuous action space that is only bounded by maximum and minimum values. The trade-off is a potentially less accurate and less refined policy – basically, the car might be slower.
If your organization is interested in learning more about Reinforcement Learning, H2O.ai, DeepRacer, or Swish, please feel free to reach out at COETeam@swishdata.com.
