Blog
Migrating to the cloud isn’t always rainbows and sunshine, so be sure to bring your raincoat and umbrella – figuratively of course.
In our recent solution brief, we discussed some of the many challenges that federal agencies frequently encounter when migrating to private and public cloud environments. These include latency problems caused by geographic disparity, insufficient network connectivity, and limited visibility into application performance that impedes monitoring and troubleshooting, among many others.
One federal cloud project in the news is the Defense Health Agency’s new electronic health records program — called Military Health System (MHS) Genesis — which delivers applications hosted by a third-party contractor to hundreds of military health facilities all over the globe via the Department of Defense Information Network (DODIN). As with other cloud deployment models, this one — which essentially is a private Software-as-a-Service (SaaS) arrangement — offers many potential benefits to a government organization, but also many potential pitfalls. In fact, early testing of MHS Genesis at a handful of medical facilities has confirmed numerous initial challenges and performance problems.

In many cases, agencies can address such challenges by adopting a structured and disciplined approach to cloud adoption that consists of four components: understanding, securing, controlling, and optimizing the cloud and the network path to it. If an agency is going to host applications with a third party, even if within a private cloud environment as MHS Genesis is, it is especially important to understand and secure the end-to-end environment as first steps. Once that is done, then agencies can provide greater focus on controlling and optimizing those environments to continuously improve performance and service levels that enhance mission velocity and productivity. Conversely, not doing so can lead to common problems such as high latency times, extended login times, frequent auto logouts, and other functional problems which are difficult to identify and negatively impact the mission.
When it comes to understanding the cloud and how the deploying application will operate within an agency’s environment, it is critical to gain end-to-end visibility of that system to thoroughly understand where problems exist and analyze their impact. Once those problems are understood, prioritized, and then effectively mitigated, then IT can set about the objectives of securing the environment; controlling end-user experience and performance KPIs for both the technical infrastructure level and the business (workflow) level; and then, finally, optimizing the environment to maximize productivity and mission velocity.
For this blog, we will focus on the first piece of that challenge: understanding the cloud environment and how the applications operating within it performance end-to-end. Swish consultants have been involved in many engagements regarding cloud adoption and SaaS performance. The best starting point is to baseline an application’s performance prior to migration to the cloud. Then model the new path to the cloud before migrating to it. Finally, monitor the application’s performance during and after the migration. Swish suggests using integrated End User Experience (EUE), Network Performance Management (NPM) and Application Performance Management (APM) solutions, such as Riverbed SteelCentral. Integrating disparate tools will streamline collaboration across teams, provide transparency and reduce Mean Time to Repair (MTTR). Key metrics to use include application transaction time, application errors, network round trip time, network retransmissions, and wait times (such as server processing, client processing and network flight time). These will help you identify key constraints in the IT architecture. At a minimum, for business metrics measure employee experience (satisfaction), business process times, business process errors, and wait time (I.E. wasted productivity).
A particularly helpful solution for this is Riverbed’s Aternity platform, which provides IT help desks and support staffs with exceptional visibility into every end user’s experience as they access and use cloud-based applications on whatever devices they are using. With Aternity, IT and help desk staffs gain insights and analysis into issues and exactly what the characteristics of those problems are, whether they concern latency, login times, frequent auto logouts that hurt productivity, unreliable network infrastructure, user errors, slow computers, or other problems. Lacking precise and accurate insights into end user problems, IT staffs and help desks are operating with an incomplete picture of the problem.
Aternity monitors every instance for every monitored user, capturing the response times it sees and comparing those response times to the norm. When performance deviates, it generates reports that detail the affected application and activity as well as the magnitude of the impact on affected users.
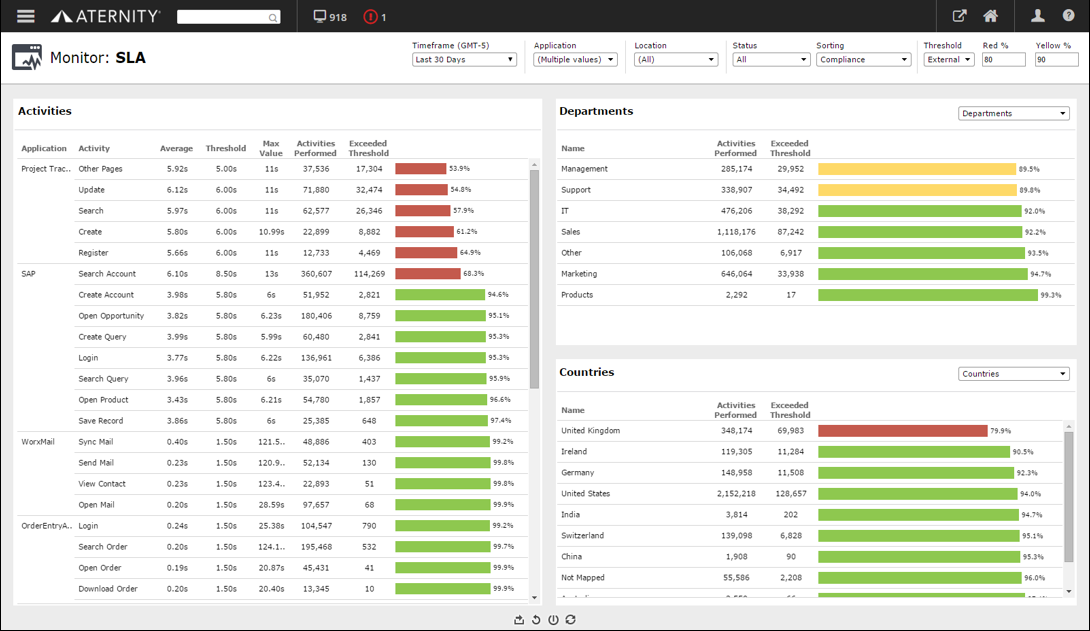
For example, in the case of a healthcare-related cloud deployment, Aternity can help validate the deployment’s impact on a prescription fulfillment application by monitoring the end user experience. This helps the IT staff understand exactly what actions an end user is taking, how long processes take, how many errors are occurring, and other metrics. If there are slowness complaints from users, for example, Aternity’s metrics help pinpoint the location, cause and severity of latency. The response times and other metrics that Aternity captures, as seen by the end user, help quantify the impact of the cloud deployment on that application by location, target server, device type, or browser.
Aternity also provides an overview of an application from an enterprise perspective, showing service level compliance for all monitored activities based on what users are seeing. The details provided of any performance deviations enable IT staffs to determine whether they are due to issues on the client or infrastructure side.
It is also critical for help desks to quickly analyze and troubleshoot problems when they arise. Aternity delivers proactive notifications when the first signs of performance deviations are discovered so that IT staffs can quickly isolate, analyze, and resolve problems. By delivering the critical contextual detail of a performance problem — including end user experience, application topology, and data center infrastructure performance — Aternity can help spot where the problem is originating so IT staffs can drill deeper to pinpoint root causes.
Swish provides solution offerings to help our enterprise clients gain insight into end-to-end performance and security. For tactical engagements Swish uses Aternity in consulting engagements to help clients analyze performance over a 30 to 90 day period for a select subset of users and applications. For example, we can monitor and analyze performance pre/during/post an application migration, so you have immediate and robust insight to inform your business decisions. For strategic engagements Swish can design or fully-manage enterprise-scale Aternity End User Experience solutions which are used by Service Desks, Application Owners and Business Analysts to track adoption, analyze experience, troubleshoot issues, validate changes, continuously improve and much more.
In summary, understanding thoroughly a new cloud environment and how an application is performing (or not) within the organization’s environment is a vital first step not only for a successful cloud migration, but mission success. The best way to get that understanding is with actual performance data for the end-user, the application and the end-to-end IT infrastructure.
Do you have your figurative raincoat and umbrella for when the cloud rains on your migration?




