Blog
So you’re migrating to the Cloud?
When an organization decides that it’s time for them to pull the trigger on migrating to the cloud, noble intent must be presumed. Even the most pessimistic among us sustainment engineers need to shelve our dour assumptions, because no rational organization would intentionally inject additional costs and complexity into their portfolio. Unsustainable, masochistic half-measures are never the desired outcome.

What do systems dependencies and CM have to do with migrating to the cloud? Almost everything. It is impossible to plan for [or predict the results of] this type of major movement without an accurate characterization of the candidate system(s). Details and nuance matter – especially when a Greenfield approach is not possible.
There aren’t many organizations out there that have the resources or flexibility required to perform a traditional, full-spectrum analysis of their IT portfolio. Further, outsourcing the study of key business processes and the systems that enable their operations is an expensive, slow proposition. Thankfully, there are mature and feature-rich Application Performance Management (APM) solutions on the market that specialize in the discovery, instrumentation, and presentation of complex IT environments.
I’m going to focus on the two heavy-hitters you’ll find occupying the Northeast-most positions in Gartner’s “Magic Quadrant” for APM; AppDynamics and Dynatrace. Specifically, an on-premises deployment [as opposed to SaaS offerings].
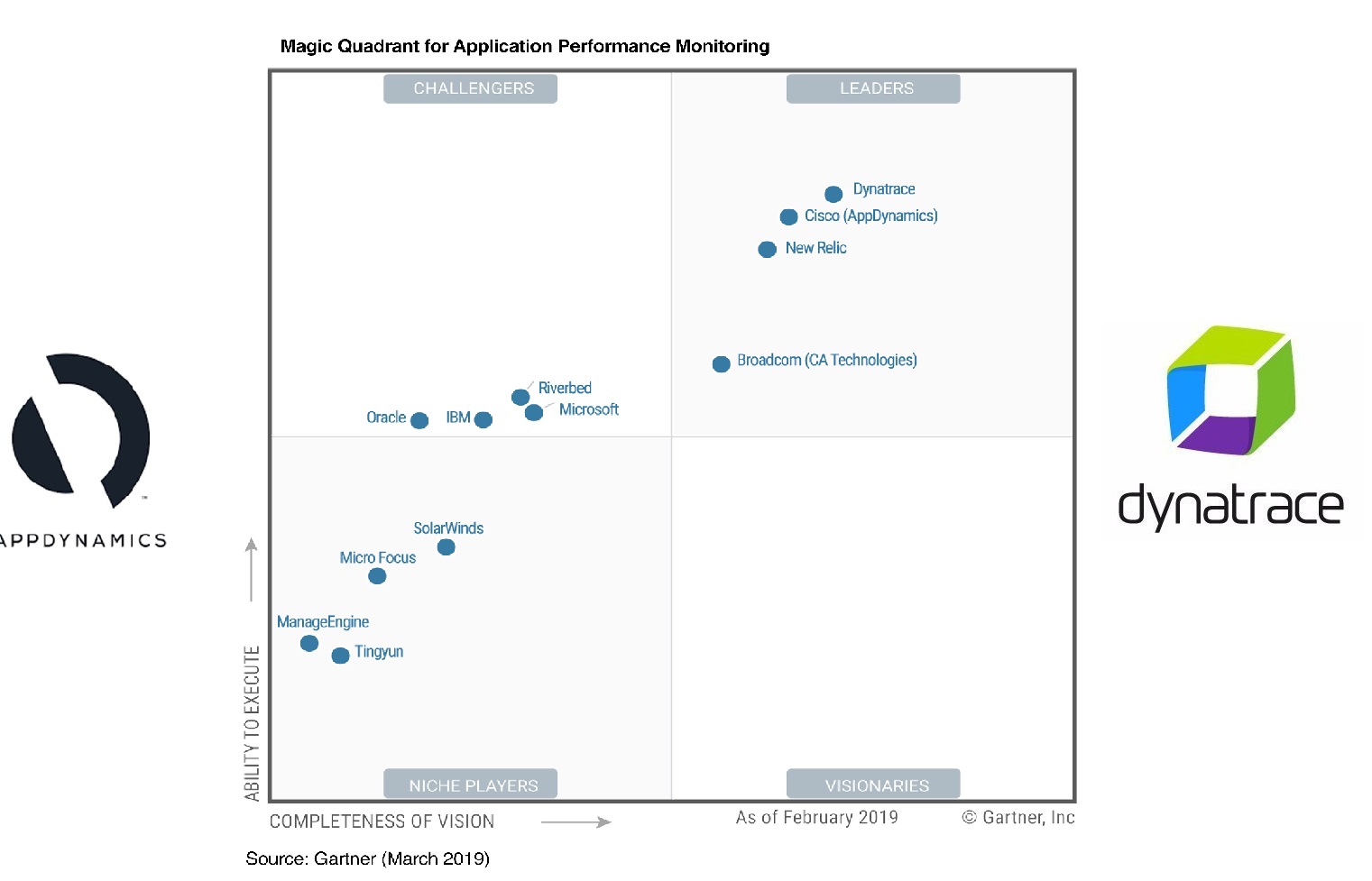
Both platforms essentially strive towards the same goals (visibility) and on the surface go about things in a similar fashion (Agents feed a collection/analysis framework). So, what makes them different? What sets one apart from the other if they seem so similar? Quite a few things.
1. Will this solution work with what I have today as well as where I would like to be in the future?
Not all APM solutions address newer generation technologies (e.g., containers, microservices) or modern engineering/support disciplines (e.g., DevOps, Agile). Taking care not to address narrow, near-term requirements at the expense of future utility is advisable.
One of the largest differentiators between the two is the sizeable list of Dynatrace’s supported technologies which includes Docker containers, microservices, and pretty much all cloud platforms. Keep in mind that this is using its OneAgent which can handle all entity types whereas AppDynamics uses multiple [sub] agents depending on the target and runtime (e.g., .NET, JVM, Database).
This is a very abbreviated list of traditional platforms their agents support:
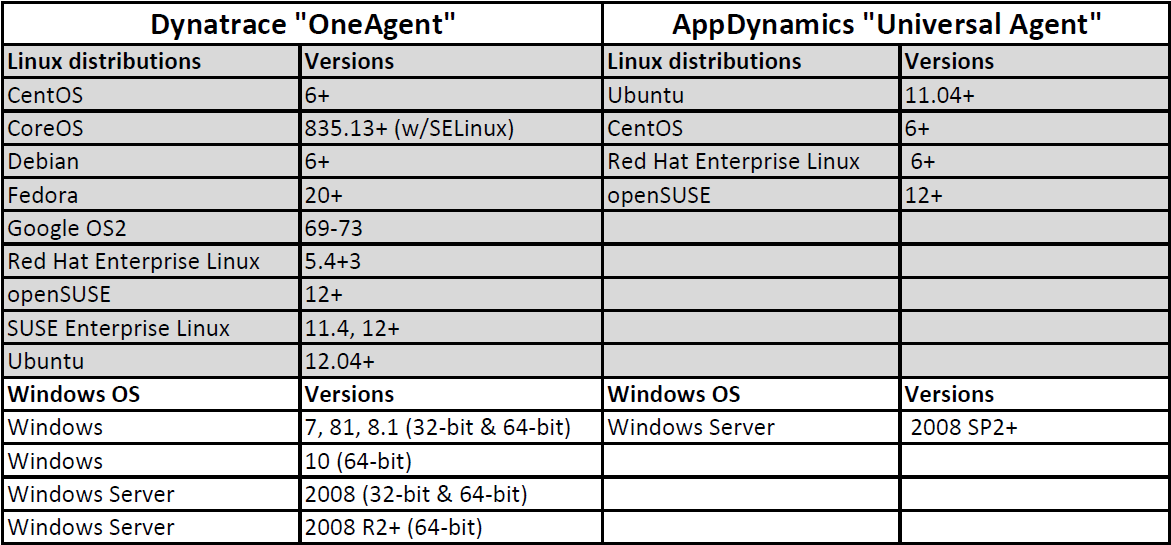
A full list of Dynatrace’s support matrix can be found here and AppDynamic’s here.
While your short-term goals might be to focus on a narrow list of business applications, it is worth knowing the true potential of a solution (e.g., RUM, mobile, Cloud). In other words – understand the potential and limiting factors that are possible. If you’re tackling a cloud migration project, it’s understandable that you could be satisfied with a capability list that includes simply .NET and Java runtimes, but why paint yourself into a corner?
2. How difficult is it to deploy and maintain the solution?
The goal of the capability is to enhance the organization’s ability to meet the needs of the business through visibility, so the support and sustainment costs must be considered. Remember – you’re looking to extract value from your portfolio, not take on an additional support burden that could mitigate the return on your investment.
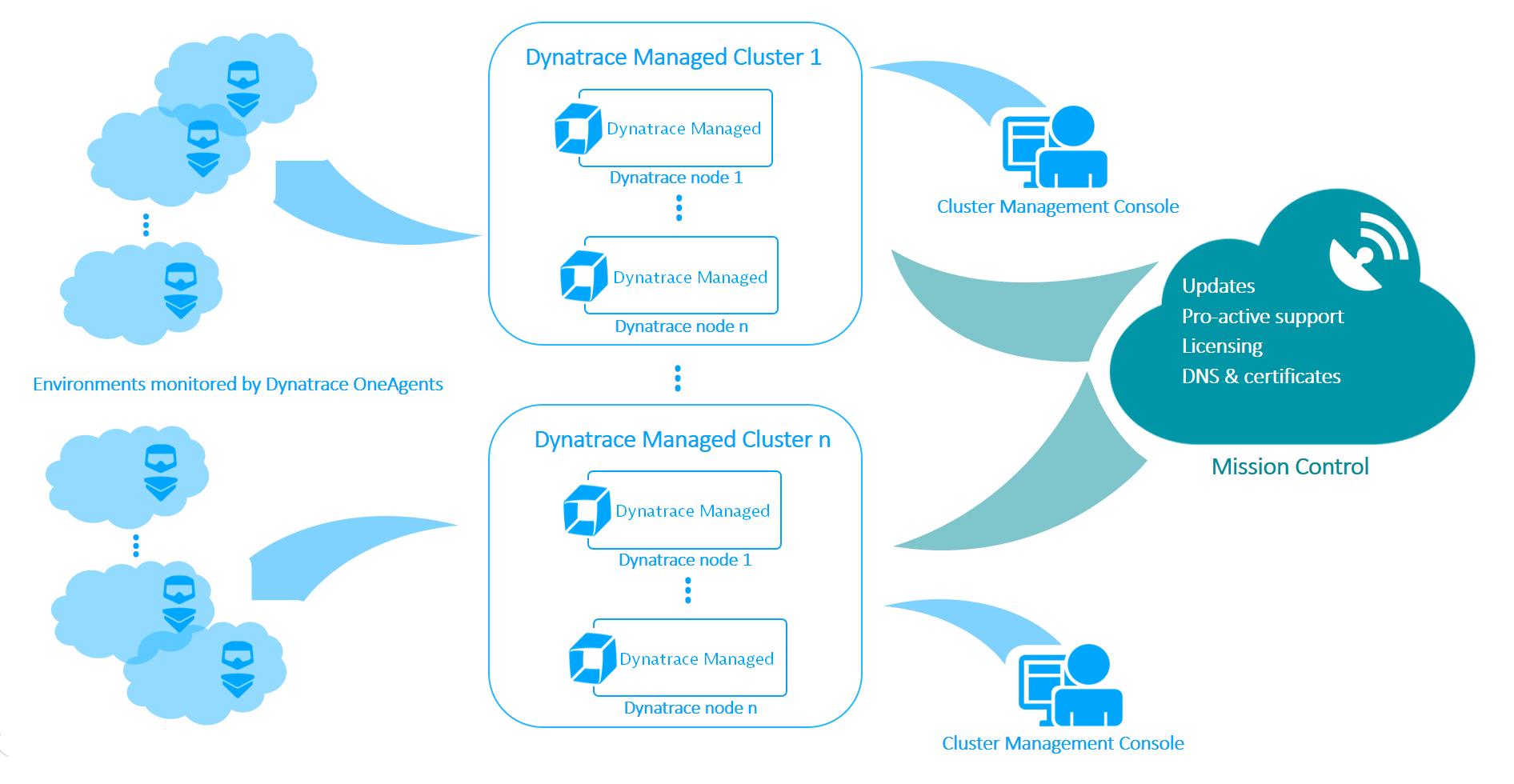
Dynatrace’s platform is actually quite elegant in terms of the number of moving parts and pieces; a single universal agent that talks to a managed node. The nodes are the brains of the operation are wholly capable individual systems.
Dynatrace’s base on-prem architecture:
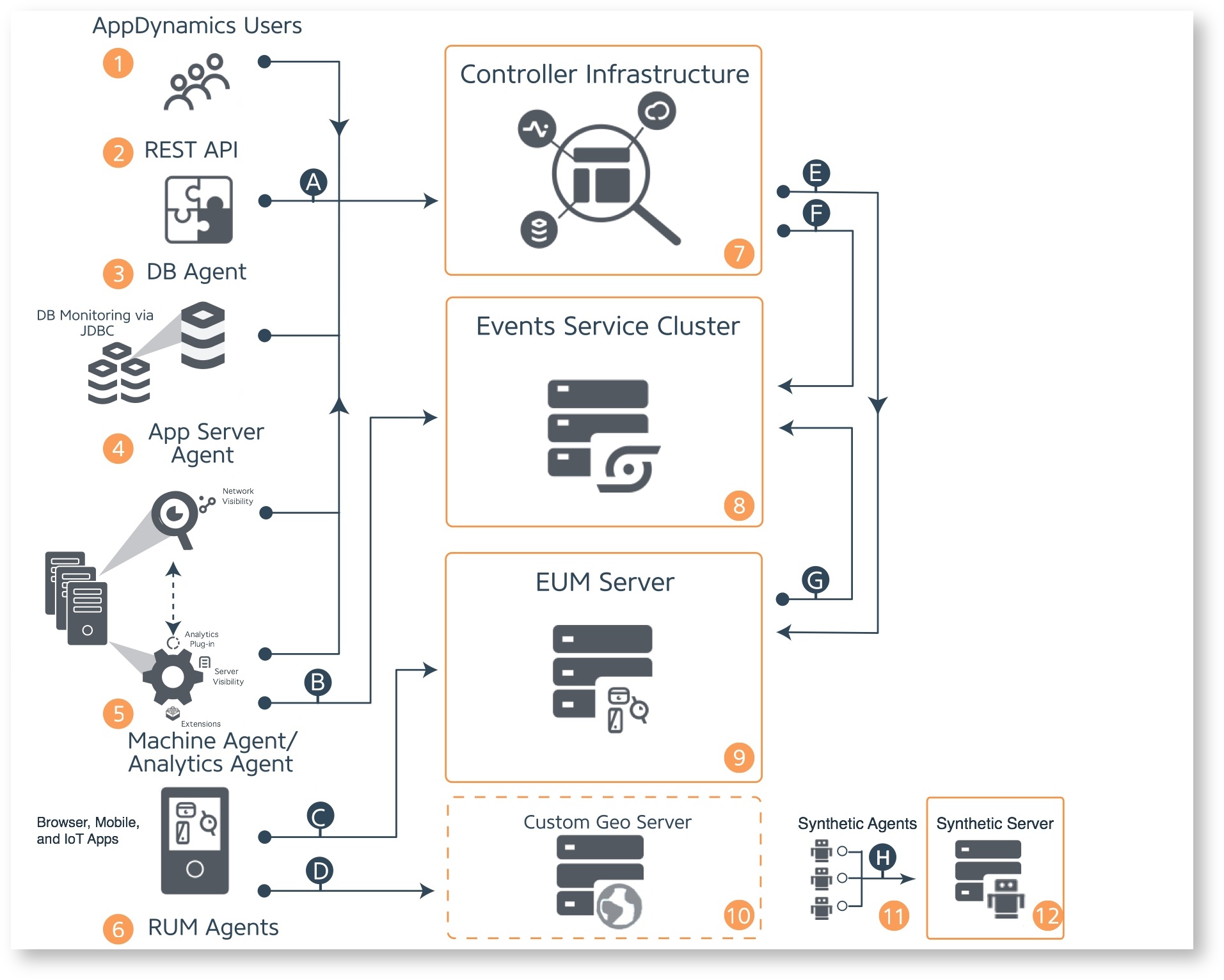
AppDynamics goes about things in a more traditional approach; a series of functional elements that orbit a central controller. As capabilities were developed, I assume they were integrated into an existing framework which results in a more complex design.
AppDynamics’ base on-prem architecture:

A successful deployment of a capability inevitably results in a future expansion of that capability once value is realized. The costs and complexity of scaling some solutions could be limiting factors. My pessimistic translation of this is “the worst-case scenario in a proof of concept, or limited initial deployment, is that it actually works…because then you need to right-size it for production.”
In the case of Dynatrace, you’re talking about N+1 of the same two objects; the Cluster Nodes and ActiveGates (if applicable). These are fully functional systems wrapped up in a uniform package – you just add more of them when you get to that point. You have the flexibility of taking it the whole way virtually [with no performance limitation caveats] if that suits you:
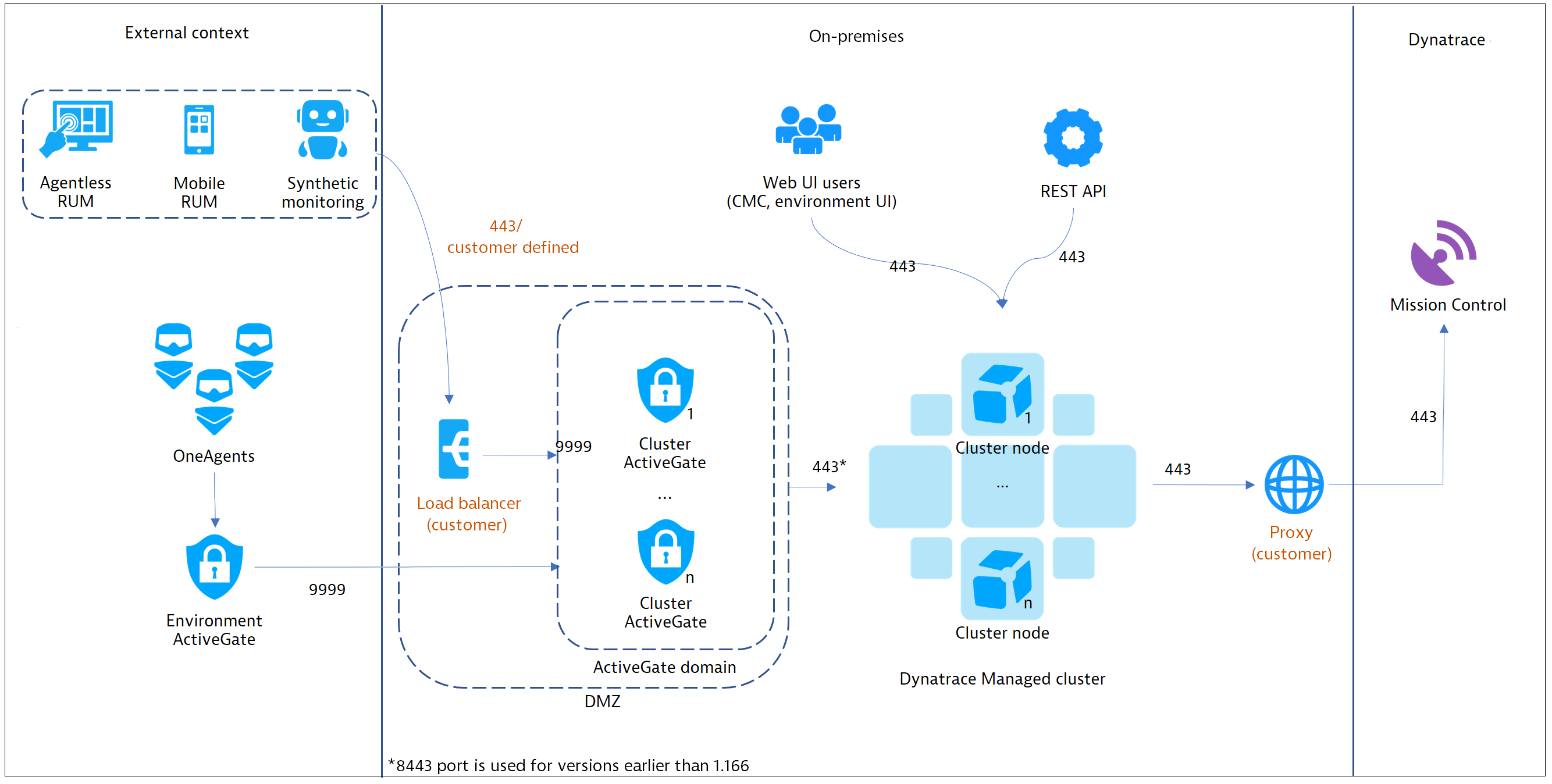
Source: Managed deployment scenarios
For AppDynamics, you’re going to need to do some math and seriously consider what your options are. Their APM platform is made up of at least 3 different infrastructure objects (Controller, EUM, and Events Servers) – each one having a unique path for scaling. Its worth noting that the Controller sizing guidance runs out of road on virtualized platforms for larger deployments, requiring you to eventually go with bare-metal. Each cluster/service object scales in its own way:
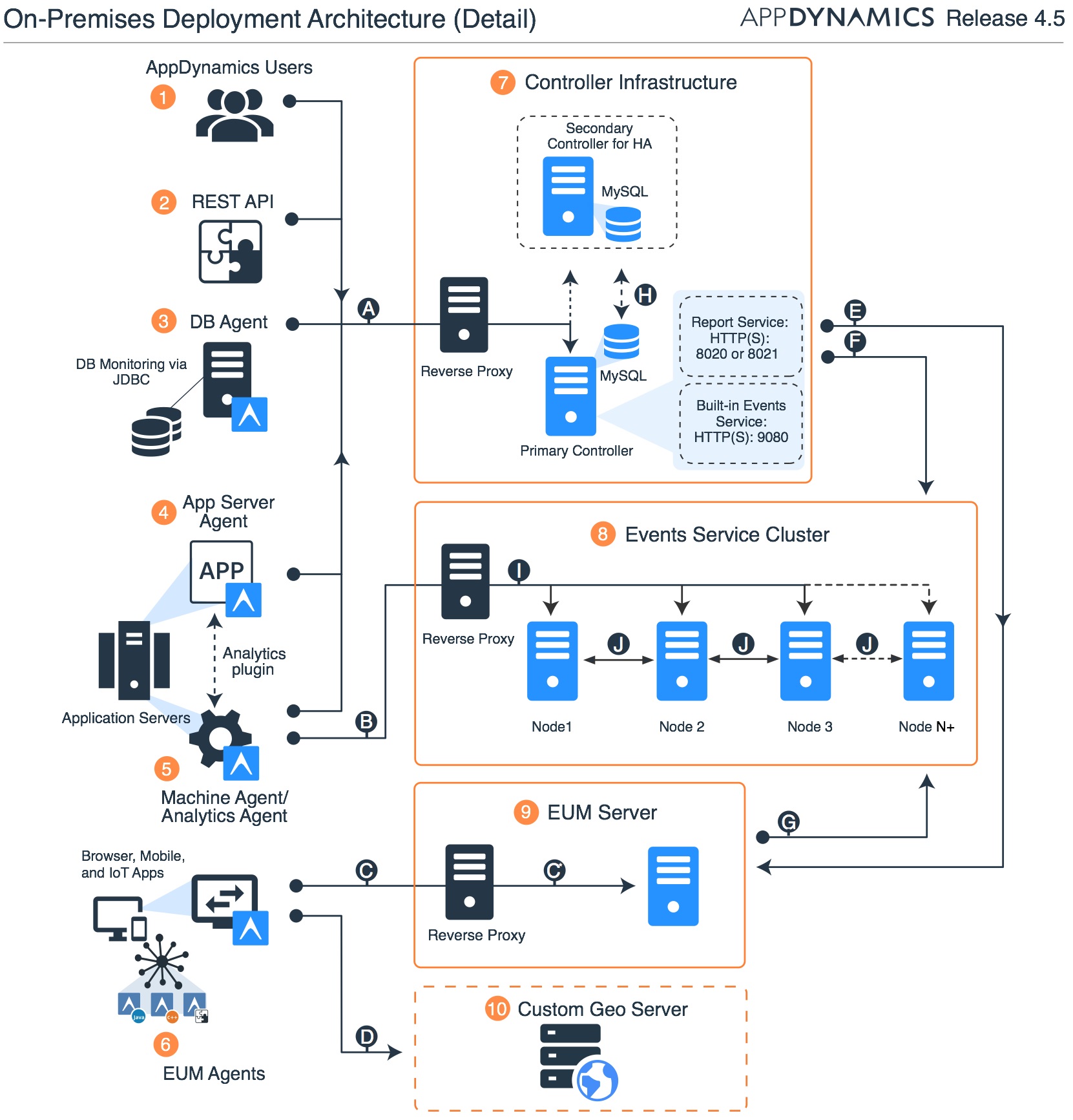
Source: App Dynamics Application Performance Platform
Note: If you want to deploy AppDynamics EUM Geolocation or Synthetic Monitoring services, those are going to be additional servers.
4. What is the depth, fidelity, and usefulness of the insights the solution will provide?
Simply generating more logs and events to manually analyze and correlate is unlikely to be the desired outcome. The last thing most organizations need is more raw data to summarize, whitelist, and ignore due to high environmental noise levels.
Further, you need to consider whether sampling/extrapolation-based approaches are adequate for making data-driven decisions. What if your sampling window is so heavily reduced to balance performance targets/scale that you miss the forest for the trees? This is not a universally necessary concession.
Final Thoughts
As I mentioned in the beginning – I come from the Operations and Sustainment world, so I put a premium on the bits and pieces of a solution that serve to make my life less difficult. Dynatrace’s APM framework was designed to get away from perpetuating the Frankenstein-esque, multi-tiered system-of-dissimilar-systems that are glued together with a panoply of network ports and design caveats. Their OneAgent is actually a singular agent and it does not require spending an unhealthy amount of time researching the nuances of a complex dependency matrix in order to add capacity/scale. It is simply leagues more elegant and intentional when compared to any Gen2 APM solution.
