Blog
On May 5th, 2021 the US Department of Defense announced its plans for “Creating Data Advantage“. Swish and Titania Solutions Group are excited to see DOD clearly stating data is a strategic asset and taking action.
In this blog post, we summarize the Defense Data Strategy, provide links to detailed DOD sources, and provide useful resources for skill development.
If you’re looking for more details watch our Qlik Public Sector “Optimizing Mission Outcomes with Intelligent Insights” webinar or ATARC “AIOps – Enabling Government Agencies To Do More with Less” webinar (w/JAIC & NASA) in which we discuss the value and best practices of data-driven insights and AI in support of the defense mission.
Creating Data Advantage Summary
Intent: Transforming the Department of Defense (DoD) to a data-centric organization is critical to improving performance and creating decision advantage at all echelons from the battlespace to the board room, ensuring U.S. competitive advantage. To accelerate the Department’s efforts, leaders must ensure all DoD data is visible, accessible, understandable, linked, trustworthy, interoperable, and secure
DOD Data Decrees
- Maximize data sharing and rights for data use: all DoD data is an enterprise resource.
- Publish data assets in the DoD federated data catalog along with common interface specifications.
- Use automated data interfaces that are externally accessible and machine-readable; ensure interfaces use industry-standard, non-proprietary, preferably open-source, technologies, protocols, and payloads.
- Store data in a manner that is platform and environment-agnostic, uncoupled from hardware or software dependencies.
- Implement industry best practices for secure authentication, access management, encryption, monitoring, and protection of data at rest, in transit, and in use.
Key Actions
- DOD Chief Data Officer (CDO) assigned responsibility for policy, guidance, and the data ecosystem (people, culture, and tech), data sharing, architecture, data lifecycle, and a data-ready workforce.
- DOD components directed to coordinate data activities by participating in the DOD Data Council by establishing appointed data leaders (unit level CDOs) and provide resources/authority to manage data and promote data literacy.
- Promote innovative investments focused on Joint All Domain Operations close interoperability gaps create joint warfighting advantage through data-driven mission command.
- Appointment of Advancing Analytics (Advana) as the single enterprise authoritative data management and analytics platform for SecDef, Deputy SecDef, Principal Staff, with input from DOD Components.
- Developing additional plans for accelerating adoption enterprise-wide (data support teams, data academies, and labs), workforce data literacy education, system reviews for data integration improvements, and delivery of a POAM to address gaps and scalability.
DOD Data Strategy Summary
The Oct 2020 DOD Data Strategy provides advice and tactics to implement the plan. A few key excerpts are provided below.
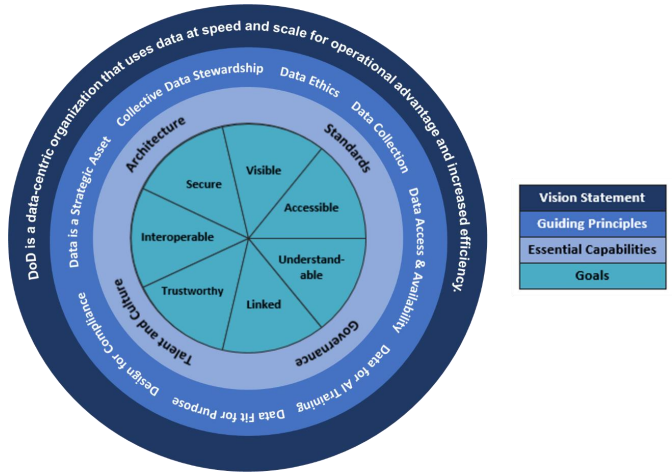
8 Guiding Principles:
- Data is a Strategic Asset – DoD data is a high-interest commodity and must be leveraged in a way that brings both immediate and lasting military advantage.
- Collective Data Stewardship – DoD must assign data stewards, data custodians, and a set of functional data managers to achieve accountability throughout the entire data lifecycle.
- Data Ethics – DoD must put ethics at the forefront of all thought and actions as it relates to how data is collected, used, and stored.
- Data Collection – DoD must enable the electronic collection of data at the point of creation and maintain the pedigree of that data at all times.
- Enterprise-Wide Data Access and Availability – DoD data must be made available for use by all authorized individuals and non-person entities through appropriate mechanisms.
- Data for Artificial Intelligence Training – Data sets for A.I. training and algorithmic models will increasingly become the DoD’s most valuable digital assets and we must create a framework for managing them across the data lifecycle that provides protected visibility and responsible brokerage.
- Data Fit for Purpose – DoD must carefully consider any ethical concerns in data collection, sharing, use, rapid data integration as well as minimization of any sources of unintended bias.
- Design for Compliance – DoD must implement IT solutions that provide an opportunity to fully automate the information management lifecycle, properly secure data, and maintain end-to-end records management.
4 Essential Capabilities
- Architecture – DoD architecture, enabled by enterprise cloud and other technologies, must allow pivoting on data more rapidly than adversaries are able to adapt.
- Standards – DoD employs a family of standards that include not only commonly recognized approaches for the management and utilization of data assets, but also proven and successful methods for representing and sharing data.
- Governance – DoD data governance provides the principles, policies, processes, frameworks, tools, metrics, and oversight required to effectively manage data at all levels, from creation to disposition.
- Talent and Culture – DoD workforce (Service Members, Civilians, and Contractors at every echelon) will be increasingly empowered to work with data, make data-informed decisions, create evidence-based policies, and implement effectual processes.
7 Goals (VAULTIS)
- Make Data Visible – Consumers can locate the needed data.
- Make Data Accessible – Consumers can retrieve the data.
- Make Data Understandable – Consumers can recognize the content, context, and applicability.
- Make Data Linked – Consumers can exploit data elements through innate relationships.
- Make Data Trustworthy – Consumers can be confident in all aspects of data for decision-making.
- Make Data Interoperable – Consumers have a common representation/comprehension of data.
- Make Data Secure – Consumers know that data is protected from unauthorized use/manipulation.
Additional Resources:
- Qlik Data Literacy Program
- Qlik World 2023
- Qlik Federal Demo Site
- O’Reilly Resource Centers
- FreeCodeCamp.org courses (Disclosure: I love open-source and donate to this project monthly)
- JAIC homepage and DOD AI Strategy
- USAF AI Annex to DOD AI Strategy
- Navy Information Superiority Vision (2020)




